What Could Possibly Go Wrong?
Key Highlights
- Resiliency ensures that the operation and purpose of the organization are fulfilled under any circumstances and as seamlessly as possible.
- An Incident Recovery plan lays out what actions to take when compromise, system failure, or performance degradation occurs, laying out failover actions.
- Continuous verification and collaboration with service providers are essential to maintaining network integrity and resilience.
- Resilience is increasingly vital due to the rise of cloud systems, distributed networks, and cybersecurity.

A New Guide to Resilience
Having authored several articles on Networking, AI, Cybersecurity and Zero Trust, this article brings all of them together.
My definition of Resiliency: Ensuring that the operation and purpose of the organization are fulfilled under any circumstances and as seamlessly as possible.
Resiliency has become a hot topic. This article begins with the big picture and then aligns with the magazine’s readership, highlighting best practices for networks, operations and security.
The Resiliency Plan
The plan is the implementation of a methodology that anticipates, withstands, and recovers from adverse events, constantly adapts to new conditions, and is continually tested. Any actions planned must prioritize and align with the operational and financial considerations of the organization.
The scope of the plan is considerable, reflecting the many causes of disruption. They can stem from poor architectural decisions, human errors, insufficient cyberattack detection or response, software or data compromises, critical infrastructure failures, poorly planned mergers, supply chain failures, untested failover procedures, etc.
It’s a documented, all-encompassing framework that must prioritize actions according to the purpose of Resiliency. It has Reactive Aspects (e.g., incident discovery and recovery) and Proactive Aspects (asset stewardship and protection—Disaster Recovery being a subset, IT, network, system and app software, security policy and ZT implementations, supply chain integrity, ZT aspects of HR, policies, etc.).
The cybersecurity mantra “you are only as strong as your weakest link” applies to Resiliency. It was so different looking back at Disaster Recovery software I wrote for a client in simpler times, 30-plus years ago. Now they are not, as the chart shows (see Figure 1.). Implementing Resiliency is like jumping into a moving car where repairs or upgrades are done while it’s in motion and under increasing attack without the passengers noticing!
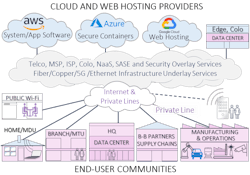
Yes, business continuity is still the organizational purpose that lives inside the data centers, the cloud-based containers where the software applications operate and micro-segmented data is stored. As we said earlier, the article now looks inside the above networks to examine best practices for infrastructure resilience.
Network, IT and Security Best Practices
Infrastructure
If you have ever wandered into your data center and wondered why a device made by a provider that no longer exists is still connected and the lights are still on, then you know the extent of the problem! Perhaps your providers’ network has failover devices that have been untested since before their last merger.
Clearly, if the infrastructure is compromised, access to the systems and software applications could be lost or degraded. Tier 1 service providers must provide alternate paths even if the performance is downgraded. So, best practices involve ensuring that there are physically separated routes to the network; should one path fail, then there must be a way of prioritizing key applications or data access. (See Figure 2.)
Prevention
It’s important in today’s complex Ransomware as a Service exploits that threats be detected before they strike. My article in the spring issue of this year investigated breach detection (see cybyr.com/assumebreach).
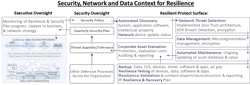
Asset Stewardship
Threats that target vulnerable asset systems and applications software, intellectual property, databases, and customer-sensitive data must be checked, encrypted, and securely backed up. The Figure 2 chart requires that backups be made without connection to the internet to enhance their integrity. It may be inconvenient but having a physical or air-gapped backup is preferred.
The chart also shows microsegmentation—the separation of software apps and data so that a compromise is limited to a small element of the system.
Verification
Best practices demand that data and systems are restored and then verified. For example, checking to see that they are malware-free.
In larger organizations, mere duplication of key systems may not be sufficient, especially when the infrastructure spans several countries connected via local Telcos and MSPs.
If It Isn’t Tested (Regularly), Then It Isn’t Resilient.
This owns the title of this piece, “What could possibly go wrong?” My decade of working for a network test company showed that the unexpected usually happens. New architectures throw up unexpected challenges or unacceptable performance occurs in failover mode. Everything must be examined.
Network infrastructure and services change or are “improved” frequently and must be assessed. This applies to the integrity of the networks, Cloud or branch-based services, connected devices and protective security software. This is pure Zero Trust thinking applied to networks and software.
Many features that enable failovers should be tested once and then again when software changes are automatically updated. The automatic discovery of what is operating in the network is key.
This necessarily involves collaboration and verification with service providers. We all know that poor regression testing from software suppliers, unverified by their customer, can be disastrous. Interrelated software may have similar resilience issues, but that is not in the scope of this article.
An Incident Recovery Plan
An Incident Recovery plan lays out what actions to take when compromise, system failure, or performance degradation occurs, laying out failover actions. The priority is always the integrity of mission-critical systems and data.
Background for the Article
For the last several months, I have been working in a Cloud Security Alliance group specifically focused on the Zero Trust aspects of Resilience, including the application of the European Digital Operational Resilience Act. As it evolved, I wanted to see how this important topic could translate into actions for ISE readers, and I hope that was achieved.
Conclusion
Due to the increasing use of Cloud systems, distributed networks and, of course, cybersecurity, Resilience has become another business imperative, so organizations are not victims of disruption, as in “How soon can we make our plan robust, tested and integrated into everything we do?”
We have only scratched the surface of this monster topic to help those in the world of IT and secure networking get a sense of the difference they can make to the success of their organization. As always, this article is part of a longer discussion on the topic. The story continues at cybyr.com/resilience.
About the Author

Mark Fishburn
Provider of Strategic Network, Cybersecurity, Software, and Marketing Services
Mark is President of cybyr.com and has five decades of experience in software, networking, and security. He is a member of ONUG, Mplify, and CSA network and security working Groups, CISA contributor and publisher of the Holistic Cybersecurity book: Hey Who Left The Back Door Open? For more information, or to give feedback, email [email protected] or follow him on LinkedIn.